虚拟化:从 vt-x 到 kvm 到 qemu 到 fuchsia machina
为了阐述实现一个虚拟化平台需要做什么事情,我们先自底向上地看一下,qemu/kvm 在 intel 平台是怎么样虚拟出一个客户机的。这一部分的内容主要来自于文章 Intel Virtualisation: How VT-x, KVM and QEMU Work Together。该文章最大的问题是任何参考资料可供进一步研究。我对其进行了自由翻译,并添加了一些参考资料。在了解了虚拟化的软件和硬件架构的基础知识之后,我们将给出一个具体的例子,将所有的事物通过一个简单的代码片段串到一起。
VT-x是英特尔的CPU虚拟化技术的名字。KVM是使用VT-x实现虚拟化的一个Linux内核的组件。QEMU是一个用户空间应用程序,它允许用户创建虚拟机。QEMU可以利用KVM实现高效的虚拟化。在这篇文章中,我们将讨论这三种技术是如何一起工作的。
虚拟化101
在进入主要讨论之前,让我们先谈谈一些基础知识。关于虚拟化的一个一般介绍可见 Operating Systems: Three Easy Pieces Virtual Machines。与虚拟化相关的是仿真———简单地说,伪造硬件。当你使用QEMU或VMWare创建基于ARM处理器的虚拟机,但你宿主机具有x86处理器时,QEMU或VMWare将需要仿真(伪造)ARM处理器。下文谈论虚拟化时,我们指的是硬件辅助虚拟化,即虚拟机的处理器与宿主机的处理器相同,并且可以通过硬件的帮助实现的性能更强的虚拟化技术。通常与虚拟化混为一谈的是一个更加独特的容器化概念。容器化主要是一个软件概念,它建立在操作系统对资源的抽象的基础上,如进程标识符、文件系统和内存消耗限制。这是一种操作系统层面的虚拟化技术,和其他操作系统层面的虚拟化技术一样,它不能虚拟出不同于宿主机之外的客户机。在这篇文章中,我们将不再讨论容器。
典型的VM设置如下所示:
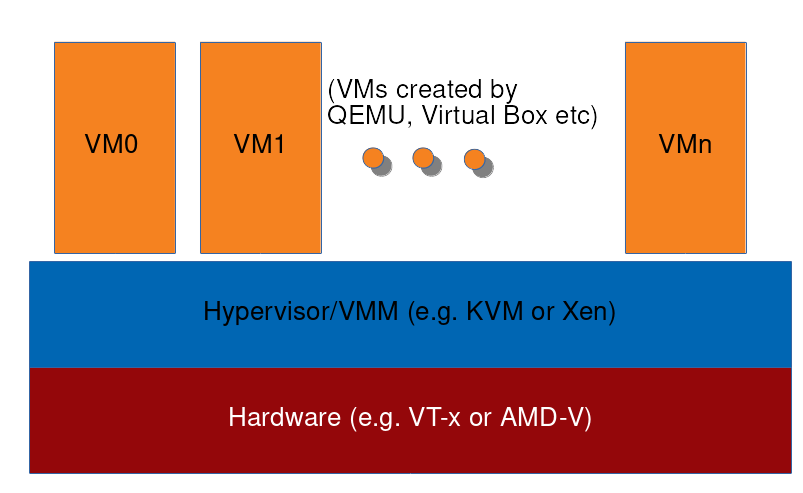
最低层是支持虚拟化的硬件。然后,取决于 hypervisor 的类型,如果是 type 1 hypervisor(如xen),则硬件之上直接运行着hypervisor或虚拟机监视器(VMM),如果是 type 2 hypervisor(如 Virtualbox),则运行着一个通用的操作系统以及操作系统之上的 hypervisor。有意思的是,KVM可以说是介于 type 1 和 type 2 之间。因为 hypervisor 实际上是Linux内核,装载了KVM模块的 Linux 内核(kvm 一般被认为是 type 2 类型虚拟机)。换句话说,KVM是一组内核模块,当加载到内核Linux时,它将内核变成 hypervisor。在hypervisor之上,在用户空间,放置最终用户直接与之交互的虚拟化应用程序———QEMU、firecracker等。然后,这些应用程序创建运行自己操作系统的虚拟机,并被hypervisor管控。
最后,虚拟化还有”全”和”半”虚拟化的两种类别。完全虚拟化是指在虚拟机内部运行的操作系统是被真实硬件上运行的操作系统完全虚拟出来的。半虚拟化是指虚拟机内部的操作系统意识到它正在被虚拟化,因此运行方式和全虚拟化稍有不同。它可以通过叫做 hypercall 的手段与 hypervisor 进行交互。
VT-x
VT-x是英特尔64和IA-32架构的中央处理器虚拟化。对于英特尔的安腾,有VT-I。对于输入/输出虚拟化,有VT-d。AMD也有称为AMD-V的虚拟化技术。我们只关心VT-x。关于VT-x的最详尽和最权威的资料是 Intel® 64 and IA-32 Architectures Software Developer Manuals。一个基于 VT-x 的 hypervisor 教程可见 5 Days to Virtualization: A Series on Hypervisor Development。
在VT-x下,中央处理器以两种模式之一运行:root和非root 模式。这些模式与实地址模式、保护模式、长模式等正交,也与特权环(privilege rings)正交。可以说,它们形成了一个新的”平面”。hypervisor 在root模式下运行,虚拟机在非root模式下运行。在非root模式下,只和运算相关的CPU的代码的执行方式和无虚拟化CPU代码没有太大差别,这意味着虚拟机绑定CPU的操作大多以本机速度运行。然而,它没有完全的自由。
特权指令是CPU上所有可用指令的子集。这些指令只有在CPU处于更高特权状态时才能执行,例如当前特权级别(CPL)0(其中CPL 3是最低特权)。这些特权指令的子集是我们所说的”全局状态改变”指令———那些影响中央处理器整体状态的指令。例子是那些修改时钟或中断寄存器,或者写入控制寄存器(用来改变root模式的操作)的指令。这个较小的敏感指令子集是非root模式不能执行的。
VMX和VMCS
虚拟机扩展(VMX)是为了方便VT-x而添加的指令。让我们看看其中的一些指令,以便更好地理解VT-x是如何工作的。
VMXON:在执行此指令之前,没有root模式与非root模式的概念。中央处理器的操作就像没有虚拟化一样。必须执行VMXON才能进入虚拟化。VMXON之后,中央处理器立即处于root模式。
VMXOFF:VMXON的逆操作,VMXOFF退出虚拟化。
VMLAUNCH:创建一个虚拟机实例并使其进入非root模式。我们将在稍后介绍VMCS时解释”虚拟机实例”的含义。现在把它想象成在QEMU或VMWare中创建的特定虚拟机。
VMRESUME:让现有VM实例恢复运行。
当虚拟机试图执行在非root模式下被禁止的指令时,CPU立即以类似陷阱(trap)的方式切换到root模式。这称为虚拟机退出(VM Exit,此处并非客户机关机,而是客户机暂停运行,等待宿主机hypervisor处理)。
综上,CPU以正常模式启动,hypervisor 执行VMXON以root模式启动虚拟化,执行VMLAUNCH创建VM实例并进入非root模式,VM实例运行自己的代码,就像在本机运行一样,直到它尝试一些被禁止的东西,这导致VM Exit并且执行程序将切换到root模式下的hypervisor。hypervisor采取行动处理虚拟机退出的原因,然后执行VMRESUME重新进入该虚拟机实例的非root模式,这使得虚拟机实例恢复其操作。root模式和非root模式之间的这种交互是硬件虚拟化支持的本质。
当然,上面的描述留下了一些空白。例如,hypervisor如何知道虚拟机退出的原因?是什么让一个虚拟机实例与另一个不同?这就是VMCS(Virtual Machine Control Structure)的用武之地。VMCS代表虚拟机控制结构。它是物理内存上的一个4KiB大小的块,包含上述进程工作所需的信息。这些信息包括虚拟机退出的原因以及每个虚拟机实例独有的信息,因此当中央处理器处于非root模式时,是VMCS决定它正在运行哪个虚拟机实例。
你可能知道,在QEMU或VMWare中,我们可以设定虚拟机将有多少个CPU。每个这样的CPU被称为虚拟CPU或vCPU。每个vCPU有一个VMCS。这意味着VMCS存储CPU级粒度的信息,而不是虚拟机级的信息。为了读写VMCS存储的信息,我们可以使用VMREAD和VMWRITE指令。这些操作需要root模式,因此只有hypervisor才能修改VMCS。非root虚拟机可以执行VMWRITE,但不能对实际的VMCS执行,而是对”影子”(shadow)VMCS执行———这不是我们立即会关心的事情。
也有对整个VMCS实例而不是单个VMCS实例操作的指令。这些指令用于在vCPU之间切换,其中vCPU可能属于任何VM实例。VMPTRLD用于加载VMCS的地址,VMPTRST用于将该地址存储到指定的内存地址。可以有许多VMCS实例,但在任何时候只有一个被标记为当前和活动。VMPTRLD将特定的VMCS标记为活动。然后,当执行VMRESUME时,非root模式虚拟机使用该活动的VMCS实例来知道它作为哪个特定的虚拟机和vCPU执行。
这里值得注意的是,上面所有的VMX指令都需要CPL级别0,所以它们只能从Linux内核(或其他操作系统内核)内部执行。
VMCS的具体数据结构可以见 VMCS layout。概括来说,VMCS存储两种类型的信息:
- 上下文信息,其中包含在root和非root之间转换期间要保存和恢复的CPU寄存器值。
- 控制信息,该信息确定VM在非root模式下的行为。
更具体地说,VMCS分为六个部分。
- 客户机状态存储。VM退出时的vCPU状态。在VMRESUME上,vCPU状态从这里恢复。
- 宿主机状态存储。VMLAUNCH和VMRESUME上的主机CPU状态。在VM退出时,主机CPU状态从这里恢复。
- 决定虚拟机在非root模式下的行为的虚拟机执行控制字段。例如,hypervisor可以在虚拟机执行控制字段中设置一个位,这样,每当虚拟机试图执行RDTSC指令读取时间戳计数器时,虚拟机就会退出到hypervisor。
- 决定虚拟机退出的行为的虚拟机退出控制字段。例如,当虚拟机退出控制部分中的一个位被设置时,每当有虚拟机退出时,调试寄存器DR7就会被保存。
- 决定虚拟机进入(VM Entry)行为的虚拟机进入控制字段。这是VM退出控制字段的对应部分。一个对称的例子是,在该字段中设置一个位将导致VM总是在VM进入时加载DR7调试寄存器。
- 虚拟机退出信息字段。告诉hypervisor退出发生的原因,并提供其他信息。
我们这里简略地谈谈硬件虚拟化支持的其他方面技术。比如,虚拟机内部的虚拟到物理地址转换是使用名为扩展页表(Extended Page Tables,EPT)的VT-x功能完成的。翻译后备缓冲区(Translation Lookaside Buffer,TLB)用于缓存虚拟到物理的映射,以保存页表查找。TLB的查询语义也需要随之改变以适配虚拟机。真实机器上,高级可编程中断控制器(Advanced Programmable Interrupt Controller,APIC)负责管理中断。在虚拟机中,这也是虚拟化的,虚拟中断可以由VMCS中的一个控制字段控制。输入输出是任何机器操作的主要部分。虚拟化I/O没有被VT-x覆盖,通常在用户空间中进行仿真或由VT-d加速。
KVM
基于内核的虚拟机(Kernel-based Virtual Machine,KVM)是一组Linux的内核模块,加载后,Linux内核将变成hypervisor。Linux作为操作系统继续其正常操作,但也为用户空间提供hypervisor设施。KVM模块可以分为两种类型:核心模块和机器专用模块。kvm.ko是总是需要的核心模块。根据主机CPU,需要机器专用模块,如kvm-intel.ko或kvm-amd.ko。可以料想,kvm-intel.ko使用了我们上面在VT-x部分描述的功能。执行VMLAUNCH/VMRESUME、设置VMCS、处理虚拟机退出等的正是KVM。值得一提的是,AMD也有自己的虚拟化技术AMD-V,而它也有自己的指令,它们被称为安全虚拟机(Secure Virtual Machine,SVM)。在arch/x86/kvm/下,你可以找到名为svm. c和vmx. c的文件。这些文件分别包含处理AMD和英特尔虚拟化设施的代码。
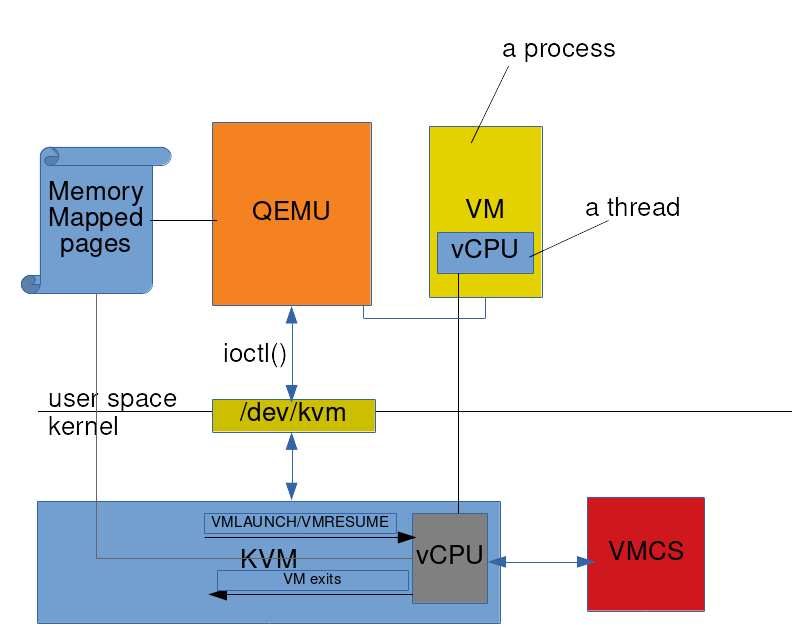
KVM通过两种方式与用户空间程序(在我们的例子中是QEMU)交互:通过设备文件/dev/kvm和内存映射页。内存映射页用于QEMU和KVM之间的批量数据传输。更具体地说,每个vCPU有两个内存映射页,它们用于内核中QEMU和VM之间的大容量数据迁移。
/dev/kvm是KVM公开的主要应用编程接口。它支持一组”ioctl”接口,允许QEMU管理虚拟机并与它们交互。KVM中最低的虚拟化单元是vCPU。一切都建立在它的基础上。/dev/kvm应用编程接口是一个三级层次结构。
- 系统级:调用此API操作整个KVM子系统的全局状态。除其他外,这用于创建VM。
- VM级别:对特定VM处理的此API的调用。通过调用此API创建vCPU。
- vCPU级别:这是粒度最低的应用编程接口,处理特定的vCPU。由于QEMU为每个vCPU指定了一个线程(参见下面的QEMU部分),对该应用编程接口的调用是在用于创建vCPU的同一个线程中完成的。
创建vCPU后,QEMU继续使用ioctl和内存映射页与它交互。更加具体的使用 kvm api 的教程可以参考 Using the KVM API。
QEMU
快速模拟器(Quick Emulator ,QEMU)是我们在VT-x/KVM/QEMU技术栈中考虑的唯一用户空间组件。使用QEMU,可以在英特尔主机上运行具有ARM或MIPS内核的虚拟机,但这怎么可能呢?基本上QEMU有两种模式:模拟器和虚拟机。作为模拟器,它可以伪造硬件。因此,对于运行在虚拟机中的软件来说,它可以让自己看起来像MIPS机器。它通过二进制翻译做到这一点。QEMU附带了小代码生成器(Tiny Code Generator TCG)。这可以被认为是一种高级语言虚拟机,正如JVM。例如,它将MIPS代码转换为中间字节码,然后在主机硬件上执行。
QEMU的另一种模式———作为虚拟化器———是实现我们在这里讨论的虚拟化类型的原因。作为虚拟化器,它可以利用KVM或者其他的底层技术。如上所述,它可以使用ioctl与KVM对话。
QEMU为每个虚拟机创建一个进程。对于每个vCPU,QEMU创建一个线程。这些是常规线程,它们像任何其他线程一样由操作系统调度。当这些线程获得运行时间时,QEMU为运行在其虚拟机内的软件创建多个CPU的印象。QEMU本身源于仿真,它可以仿真I/O,这是KVM可能无法完全支持的。比如,它可以仿真主机上没有的但是虚拟机需要的特定串口。现在,当虚拟机内部的软件执行I/O时,虚拟机退出到KVM。KVM查看原因,并将控制权连同指向输入/输出请求信息的指针传递给QEMU。QEMU为该请求模拟输入/输出设备———从而为虚拟机内部的软件实现它———并将控制权传递回KVM。KVM执行一个VMRESUME来让虚拟机继续。
最后,让我们用图表总结一下整体情况:
Machina
现在让我们把所有的东西都总结到一起,让我们看看 Fuchsia 虚拟机监视器(也叫 machina)是怎样创建并运行一个简单的虚拟机的。下面是 Fuchsia 的一个用于测试 hypervisor 的集成测试代码片段。下面是
TEST(Guest, VcpuEnter) {
TestCase test;
ASSERT_NO_FATAL_FAILURE(SetupGuest(&test, vcpu_enter_start, vcpu_enter_end));
ASSERT_NO_FATAL_FAILURE(EnterAndCleanExit(&test));
}
这个代码片段会先通过 SetupGuest 创建一个客户机,之后进入并运行客户机。下面分别是这两个函数的代码。
// Setup a guest in fixture |test|.
//
// |start| and |end| point to the start and end of the code that will be copied into the guest for
// execution. If |start| and |end| are null, no code is copied.
void SetupGuest(TestCase* test, const char* start, const char* end) {
ASSERT_EQ(zx::vmo::create(VMO_SIZE, 0, &test->vmo), ZX_OK);
ASSERT_EQ(zx::vmar::root_self()->map(kHostMapFlags, 0, test->vmo, 0, VMO_SIZE, &test->host_addr),
ZX_OK);
cpp20::span<uint8_t> guest_memory(reinterpret_cast<uint8_t*>(test->host_addr), VMO_SIZE);
// Add ZX_RIGHT_EXECUTABLE so we can map into guest address space.
zx::resource vmex_resource;
ASSERT_EQ(GetVmexResource(&vmex_resource), ZX_OK);
ASSERT_EQ(test->vmo.replace_as_executable(vmex_resource, &test->vmo), ZX_OK);
zx::resource hypervisor_resource;
ASSERT_EQ(GetHypervisorResource(&hypervisor_resource), ZX_OK);
zx_status_t status = zx::guest::create(hypervisor_resource, 0, &test->guest, &test->vmar);
ASSERT_EQ(status, ZX_OK);
zx_gpaddr_t guest_addr;
ASSERT_EQ(test->vmar.map(kGuestMapFlags, 0, test->vmo, 0, VMO_SIZE, &guest_addr), ZX_OK);
ASSERT_EQ(test->guest.set_trap(ZX_GUEST_TRAP_MEM, EXIT_TEST_ADDR, PAGE_SIZE, zx::port(), 0),
ZX_OK);
// Set up a simple page table structure for the guest.
SetUpGuestPageTable(guest_memory);
// Copy guest code into guest memory at address `kGuestEntryPoint`.
if (start != nullptr && end != nullptr) {
memcpy(guest_memory.data() + kGuestEntryPoint, start, end - start);
}
status = zx::vcpu::create(test->guest, 0, kGuestEntryPoint, &test->vcpu);
ASSERT_EQ(status, ZX_OK);
}
我们可以看到这个代码关键在于调用了 zx::guest::create zx::vcpu::create 这两个函数,它们用于创建客户机和虚拟CPU,其背后的系统调用分别为 zx_guest_create 和 zx_vcpu_create,这两个系统调用类似于 KVM_CREATE_VM 和 KVM_CREATE_VCPU(见 Using the KVM API),在创建完客户机、设置好客户机的页表、创建虚拟CPU之后、设定好 vcpu 的 entrypoint(即初始代码运行地址),将虚拟CPU绑定到客户机之后,我们就可以进入虚拟机运行的主循环,也就是持续调用下面的 vcpu.enter 函数。
void EnterAndCleanExit(TestCase* test) {
zx_port_packet_t packet = {};
ASSERT_EQ(test->vcpu.enter(&packet), ZX_OK);
EXPECT_EQ(packet.type, ZX_PKT_TYPE_GUEST_MEM);
EXPECT_EQ(packet.guest_mem.addr, static_cast<zx_gpaddr_t>(EXIT_TEST_ADDR));
#if __x86_64__
EXPECT_EQ(packet.guest_mem.default_operand_size, 4u);
#endif
if (test->interrupts_enabled) {
ASSERT_FALSE(ExceptionThrown(packet.guest_mem, test->vcpu));
}
}
vcpu.enter 实际上是系统调用 zx_vcpu_enter 的一个 wrapper。这个系统调用类似于 kvm 的 KVM_RUN,它会让虚拟机一直在硬件CPU上运行,直到运行至某些高特权的指令或者触发某个hypervisor 设置的 trap,这时它会被强制退出(也叫 vm exit)。每次 vm exit 后,hypervisor 都会根据处理器提供的 exit information 以及当前运行的指令集判断 vcpu 想要进行什么操作,hypervisor 会模拟这些操作,模拟完成后通过 zx_vcpu_enter 继续运行客户机。这个被称为 trap and emulate 的过程对客户机是无感知的,所以我们才能够实现虚拟化。hypervisor 运行一个客户机的过程就是,一个 trap and emulate 的过程,而 linux 的 kvm 和 fuchsia 的 machina 正是各自的 kernel 提供的让这个 trap and emulate 过程变得更容易的接口。上面说的虚拟化过程正是 Popek 和 Goldberg 虚拟化。感兴趣的可以查阅原始论文。
细心的读者可能发现了,此处介绍的还是 cpu 和内存的虚拟化。那么类似于 qemu 的 IO 虚拟化又是什么样子的呢?此处不再深入讨论,你可以通过查阅 src/virtualization/lib/virtio-device/ 和 src/virtualization/bin/vmm/main.cc 找到更多信息。
关于虚拟化的更深入介绍可以查阅 Hardware and Software Support for Virtualization,该书深入地介绍了一些硬件和软件虚拟化手段。从这书可以找到本文没有提起的一些其他虚拟机监视器的实现,IO 和中断虚拟化的实现,arm 64 平台的虚拟化支持,并且它还提供了详尽的参考文献,是一本不可多得的好书。